Recipe Recommender System with VAE

Introduction
Data was downloaded from Kaggle and originally is from food.com. The recipes dataset contains 522,517 recipes from 312 different categories. This dataset provides information about each recipe like cooking times, servings, ingredients, nutrition, instructions, and more.
Workflow Overview
The steps we took for building the recommender system are as follows:
-
Data Download and Cleaning
We first download the datasets and clean them, handling missing values and inconsistencies. - Preprocessing
- Scale numeric data
- Create vector embeddings for textual data such as ingredients and instructions
- Explain the motivation for using a Variational Autoencoder (VAE)
- Modeling with Variational Autoencoder (VAE)
- Build a VAE to learn latent representations of recipes
- Optimize hyperparameters for better performance
- Create a latent space for all recipes
- Recommendation
Based on liked recipes, recommend similar ones using the learned latent space.
We also provide a notebook analysis explaining why machine learning is useful for this task, and why traditional non-ML methods may not perform well for large and complex datasets.
Part 1: Data Exploration and Preprocessing
All the data exploration and preprocessing analysis can be found in the following notebook:
📁 File: Data_Exploration_Preparation.ipynb
🔗 Source: View on GitHub
After downloading the data from Kaggle (irkaal/foodcom-recipes-and-reviews), we load them into CSV files. The recipe dataframe includes columns such as:
- RecipeId, Name, AuthorId, AuthorName, CookTime, PrepTime, DatePublished, Description, Images, RecipeCategory, Keywords
- RecipeIngredientQuantities, ReviewCount, Calories, FatContent, SaturatedFatContent, CholesterolContent, SodiumContent, CarbohydrateContent, FiberContent, SugarContent, ProteinContent
- RecipeServings, RecipeYield, RecipeInstructions
In this project, we focus on the recipes only and do not use the reviews dataset.
The first preprocessing step involves exploring missing values. We inspect the dataset, identify columns with many NaN values, and remove them to simplify the analysis.
Part 2: Selecting Important Features and Handling Outliers
After removing columns with excessive missing values, we focus on the most relevant features for the model.
Numeric columns kept:
- Calories
- FatContent
- SaturatedFatContent
- CholesterolContent
- SodiumContent
- CarbohydrateContent
- FiberContent
- SugarContent
- ProteinContent
Text columns kept:
- Name
- RecipeCategory
- RecipeIngredientParts
- RecipeInstructions
Some numeric columns contain outliers. To address them, we retain only the data points within the 99.5th percentile for each column, reducing skew while preserving most of the data.
2.1 Text Embeddings with all-MiniLM-L6-v2
Before dimensionality reduction or model building, unstructured text from recipe names, ingredients, and instructions is converted into numerical form — a process called text embedding. For this, we use the all-MiniLM-L6-v2 pre-trained model.
What is MiniLM?
all-MiniLM-L6-v2 is a compact, pre-trained language model designed for generating high-quality sentence embeddings. It’s part of a family of efficient models that are faster and smaller than BERT while maintaining strong accuracy.
Why we chose this model
- Efficiency: MiniLM runs much faster and uses less memory than larger models, making it practical for large datasets.
- High Performance: Despite its size, it captures semantic relationships effectively — for instance, recognizing that “diced tomatoes and basil” and “chopped tomatoes with fresh herbs” are conceptually similar.
- Vector Output (384 Dimensions): Each recipe text is transformed into a 384-dimensional dense vector, representing its meaning and structure.
2.2 Exploring the Data & Why Use a Machine Learning Model
After scaling numeric data and generating embeddings for text data, we saved the cleaned dataset and analyzed it to explore whether clustering could group similar recipes.
📁 File: Why_ML_Model.ipynb
🔗 Source: View on GitHub
Using PCA, we found that over 50 principal components were needed to explain 98% of the variance. We also tried KMeans clustering, testing multiple values of k using the elbow method. However, the clusters did not show clear structure.
This outcome motivated us to move to a VAE-based approach, capable of learning deeper and more expressive latent features.
Part 3: Building the Variational Autoencoder (VAE)
Since traditional clustering didn’t yield strong structure, we used a VAE to learn richer latent representations of recipes.
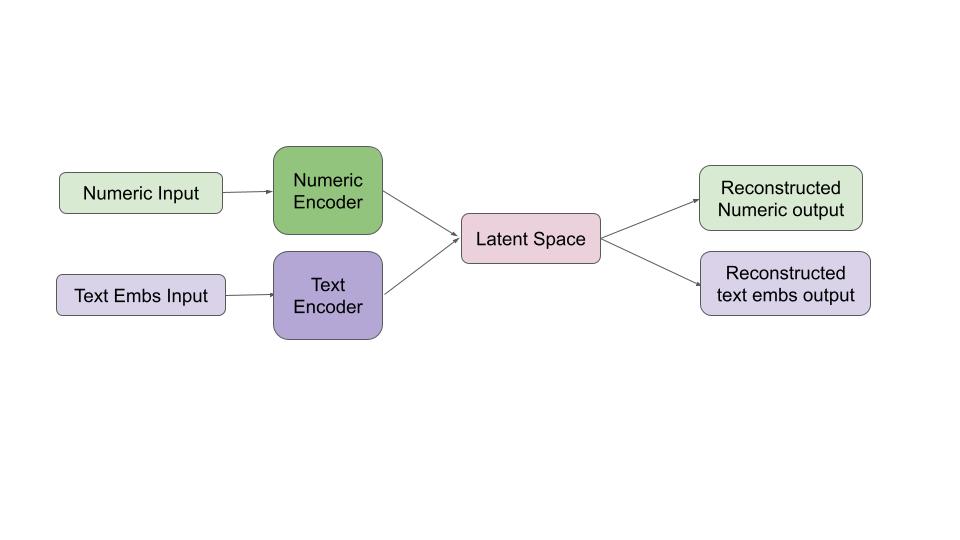
📁 File: model.py
🔗 Source: View on GitHub
The VAE architecture has three main components: Encoder, Decoder, and Loss Function.
3.1 Encoder
The encoder processes both numeric features (e.g., calories, fat, protein) and text embeddings (from names, ingredients, and instructions).
Each branch is processed through dense layers before being merged into latent variables — mu and log variance — which define the latent Gaussian distribution. Using the reparameterization trick, we sample the latent vector z.
3.2 Decoder
The decoder reconstructs numeric and text inputs from the latent vector, learning compact and meaningful representations of recipes.
3.3 Loss Function
The model optimizes a weighted combination of:
- Reconstruction Loss for numeric and text data
- KL Divergence, which regularizes the latent space
Weights balance numeric and text importance, while an adjustable KL term fine-tunes regularization.
3.4 Training the VAE
We trained the VAE with preprocessed data split into train, validation, and test sets.
Key experiments tuned the balance between reconstruction weights and the KL regularization term.
We used KL annealing, gradually increasing its weight to stabilize training.
📁 File: train.py
🔗 Source: View on GitHub
Training ran for 100 epochs with a batch size of 512. After each experiment, we saved:
- Model checkpoints
- Loss history
- Latent embeddings for the test set
This approach produced robust, interpretable representations that captured both numeric and textual recipe information.
Part 4: Analysis of Model Output and Recommendations
Post-training analysis was done in analysis.ipynb, inspecting loss curves and latent distributions for model quality.
📁 File: analysis.ipynb
🔗 Source: View on GitHub
VAE Loss Function
The model minimizes a weighted loss:
\[\mathcal{L}_{\text{total}} = \frac{1}{N} \Big( w_{\text{num}} \cdot \mathcal{L}_{\text{recon}}^{\text{num}} + w_{\text{text}} \cdot \mathcal{L}_{\text{recon}}^{\text{text}} + w_{\text{KL}} \cdot \mathcal{L}_{\text{KL}} \Big)\]Where:
- $\mathcal{L}_{\text{recon}}^{\text{num}}$ = numeric reconstruction loss
- $\mathcal{L}_{\text{recon}}^{\text{text}}$ = text reconstruction loss
- $\mathcal{L}_{\text{KL}}$ = KL divergence loss
- $w_{\text{num}}, w_{\text{text}}, w_{\text{KL}}$ are the respective weights
- $N$ = batch size
Loss plots confirmed that each weight influenced its respective component as expected, indicating stable and interpretable training.
Latent distribution visualizations showed well-behaved Gaussian structures, with minimal posterior collapse in only one configuration.
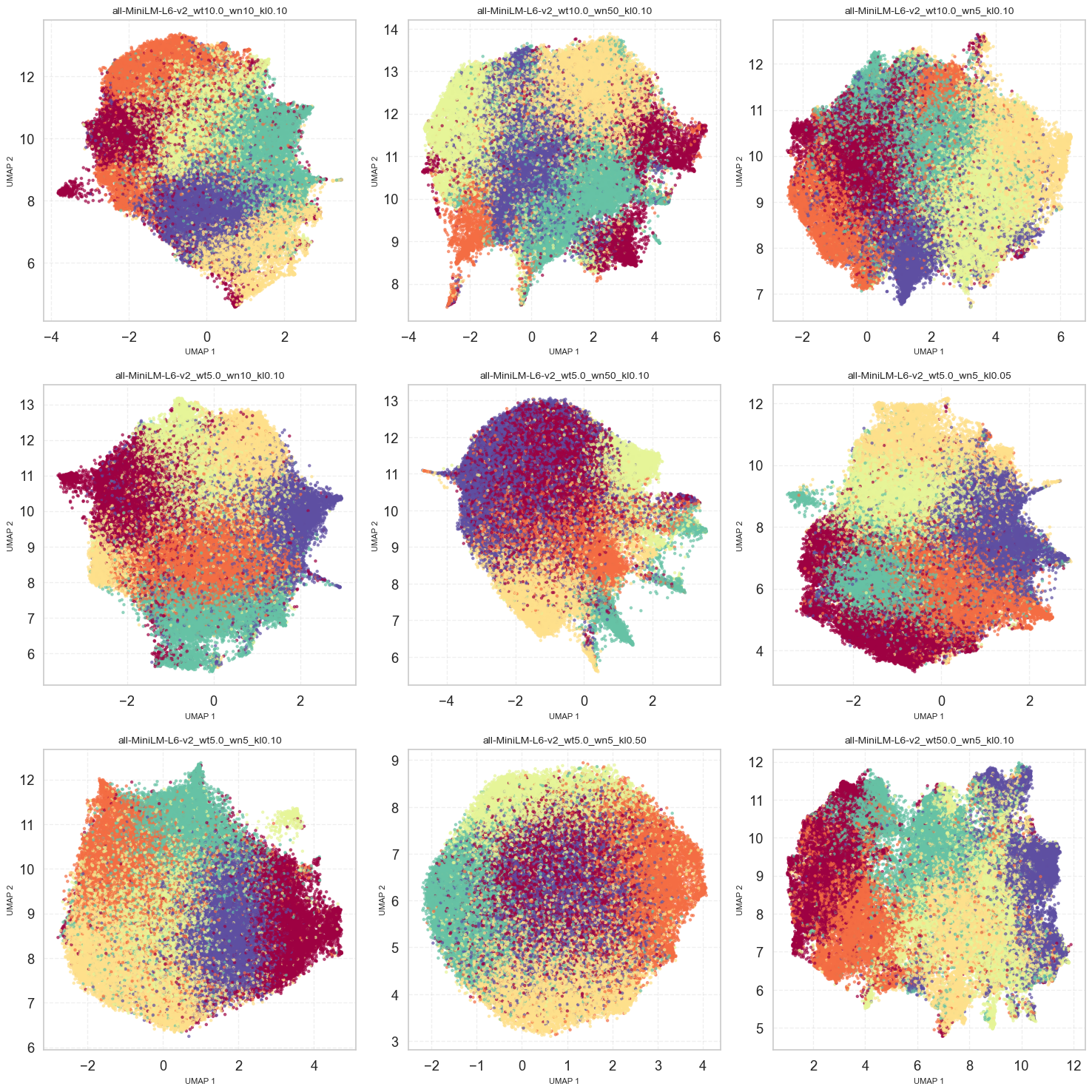
Generating Recipe Recommendations
Once trained, we used 32-dimensional latent embeddings to recommend recipes.
Using KMeans and UMAP visualization, we found organized latent spaces that reflected meaningful structure.
To ensure reliable recommendations, we used a consensus-based approach:
- Select a random set of test recipes.
- Retrieve top similar recipes from each trained model.
- Count how often each appears across models.
- Recommend only recipes appearing in at least three models.
This reduces noise and improves recommendation reliability. The output lists the original recipe with its most consistently similar ones across multiple models.
Example Recommendations
🍽️ Liked Recipe
ID: 326591
Name: Golden Syrup Russian Fudge
Instructions:
Place all the ingredients except the vanilla into a medium-heavy saucepan. Warm gently until sugar dissolves. Bring to a gentle boil for 15–20 minutes, stirring occasionally. Remove from heat, add vanilla, and beat until thick. Pour into a greased pan, let cool, and enjoy.
✅ Recommended Recipes (appearing in at least 3 models):
Recipe ID: 518256
Name: “White Caprese” Cake Gluten Free
Instructions:
Blitz almonds until finely chopped. Melt white chocolate, mix eggs with sugar and zest, combine all ingredients, bake at 170°C for 40 minutes, and dust with powdered sugar.
Recipe ID: 216030
Name: “Flaky” Oatmeal-Raisin Cookies
Instructions:
Cream sugar and butter, stir in eggs, mix in dry ingredients, add raisins and oats, scoop dough onto sheets, flatten, and bake at 350°F for 13–15 minutes.
Recipe ID: 17265
Name: $25 Pumpkin Pie
Instructions:
Prepare crust, bake partially, mix pumpkin with sugar and spices, cook until thick, whisk with cream and milk, pour into crust, bake 25 minutes, cool, and serve with whipped cream.
Recipe ID: 188928
Name: “Butter Me Bananas” French Toast
Instructions:
Mix egg, milk, vanilla, and spices; dip bread; cook on medium-high heat; mash banana with butter; spread between toast slices; top with syrup and banana slices. Serve warm and enjoy.